A decision tree is a graph that uses a branching method to illustrate every possible outcome of a decision. It applies a series of linear decisions. When we want to predict something, check each node, can select a branch to go, finally, we will reach a predicted label.
Tree classification:
- Start at a root node
- Evaluate property of that node
- Follow branch according to property evaluation to descendant node
- Descendent node can then be considered to be the root node of a subtree
- Repeat until a Leaf node is reached, and assign that predicted label
The following figure illustrates the components of tree: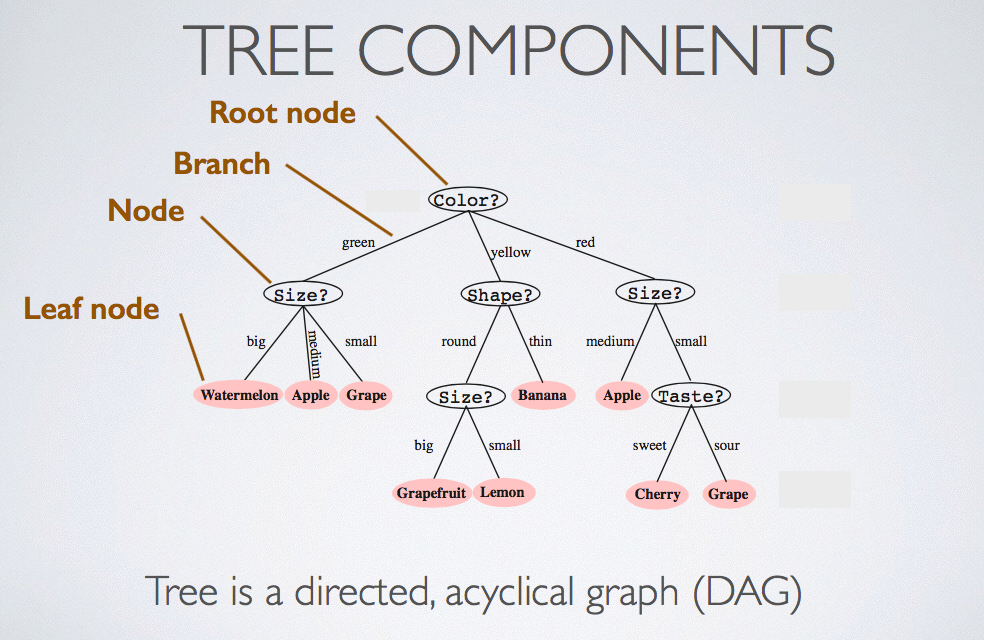
ID3 algorithm:
The definition of ID3 algorithm is it begins with the original set S as the root node. On each iteration of the algorithm, it iterates through every unused attribute of the set S and calculates the entropy H(S) (or information gain IG(S)) of that attribute. It then selects the attribute which has the smallest entropy (or largest information gain) value. The set S is then split by the selected attribute (e.g. age is less than 50, age is between 50 and 100, age is greater than 100) to produce subsets of the data. The algorithm continues to recurse on each subset, considering only attributes never selected before.
Suppose the training set contains p positive and n negative examples. Then an estimate on the information contained in a correct answer is: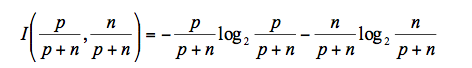
And the remainder of that attribute is: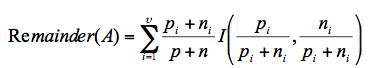
So the gain of that attribute is: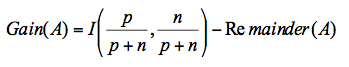
Finally, the attribute that is chosen is the one with the largest gain.
Then we can note it as the node value.
Decision tree learning:
We use the emotion_data set in this example. And all the data are on the Github, check the link at the bottom of this article. Six trees will be made to predict six emotions. Firstly, we convert the target label data to a new set only includes 1 and 0. 1 stands for this data is emotion_N. 0 stands for it is not emotion_N. Then we need to select the best attribute and the most suitable threshold (bound) at each node. We select each data at the current attribute as the threshold, and then keep track of p0, n0, p1 and n1 for each loop, calculate the I (information), R (remainder) and G (gain) for each attribute, and finally find the greatest gain. So each attribute needs to calculate 612 times for selecting the best threshold for the attribute. Then selecting the attribute which has the greatest gain for the current node.
We use struct(‘op’, [], ‘kids’, [], ‘class’, []) to make the decision tree and tree.op = [suitable_attribute, threshold] . If the training data value is less than the attribute’s threshold, we assign it to kids{1} , otherwise, kids{2} , and assign tree.kids = kids . Repeat it for every example. And then start making the next node, the steps are the same as previous. When the target data set contains only 1 or 0, we stop training this branch and set mode(target data) as the tree.class for that branch. Or if there is no attribute to select, we set mode(target data) as the tree.class for that branch. Repeat all until each branch has an end and repeat it for each emotion until six trees have been made. The following figure is what the tree should be: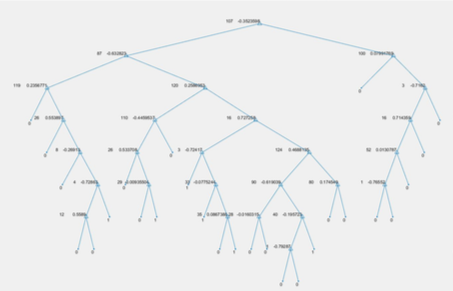
Here is the sample code for decision tree training:
|
|
Pruning:
First full train a tree, without stopping criterion, after training, prune tree by eliminating pairs of leaf nodes for which the impurity penalty is small. So tree pruning will remove branches that result in the same value no matter the value of the attribute split on, to some extents, these branches make no senses. And the optimal tree size is where the cost is the smallest possible but still having an error rate of the tree using cross validation. The most basic difference is the pruned tree has a smaller size than the original tree. On the other hand, overfitting is less likely to occur in the pruned tree as we have reduced the variance of the tree, however, it can also result in a higher bias in predicting.
Cross-validation:
Cross-validation is to split data into two sets, one for training data and another for testing data. These two should never overlap. As for 10 cross-validation, we firstly train the training data(9 size) and then use the trained tree to predict the testing data(1 size). We can calculate the error estimate. Repeat it 10 times, and then calculate the total error estimate. It can avoid overfitting.
Here is the link for downloading the sample data: