Brute force solution (Disadvantage)
In order to solve the problem of substring search, people will come up with the idea of brute force. Let’s look at an example, suppose we have a string, “ababcab”(Let’s call this string S). Then we want to check whether this string contains “abc”(Let’s call this string T). Based on the idea of brute force, we will start at the index 0(si) in S and index 0(ti) in T.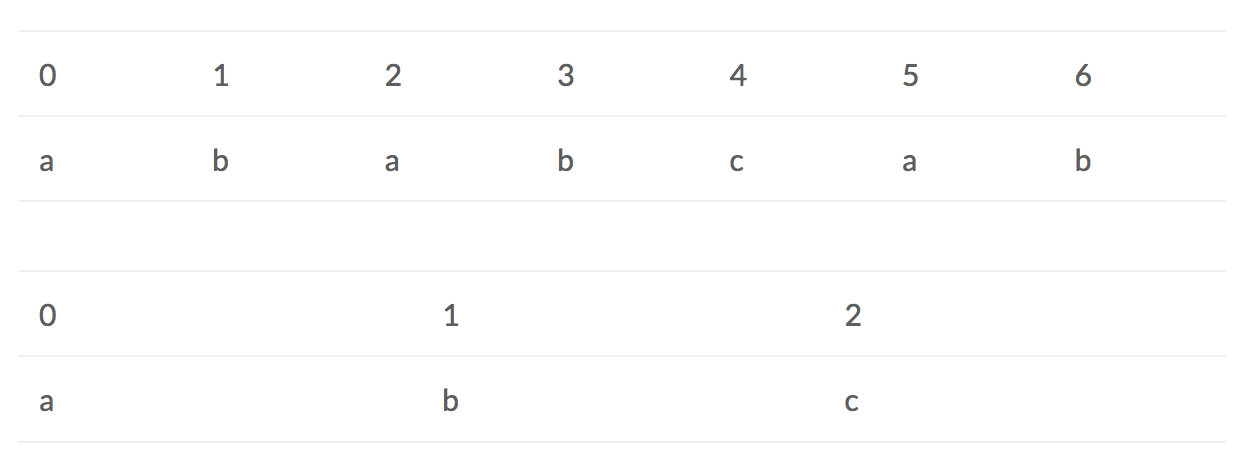
When ti = 2 and si = 2, we find that ‘c’ != ‘a’. So we start at si =1, ti =0 again. Then ‘b’ != ‘a’, so we start at si = 2, ti = 0, etc… The complexity of this algorithm is m*n. (m is the length of S, n is the length of T). So when the length of array grows bigger, it will cost a lot of time. Here we introduce the KMP algorithm.
KMP algorithm (part 1_Partial matching table):
The algorithm was conceived in 1970 by Donald Knuth and Vaughan Pratt, and independently by James H. Morris. The three published it jointly in 1977.[1]
The basic idea is compared with brute force solution, which need to move the si one by one each time, and start with the ti = 0 each time, KMP algorithm can skip those index which has been searched. The complexity of it is m+n. To explain it better let’s see the previous example again.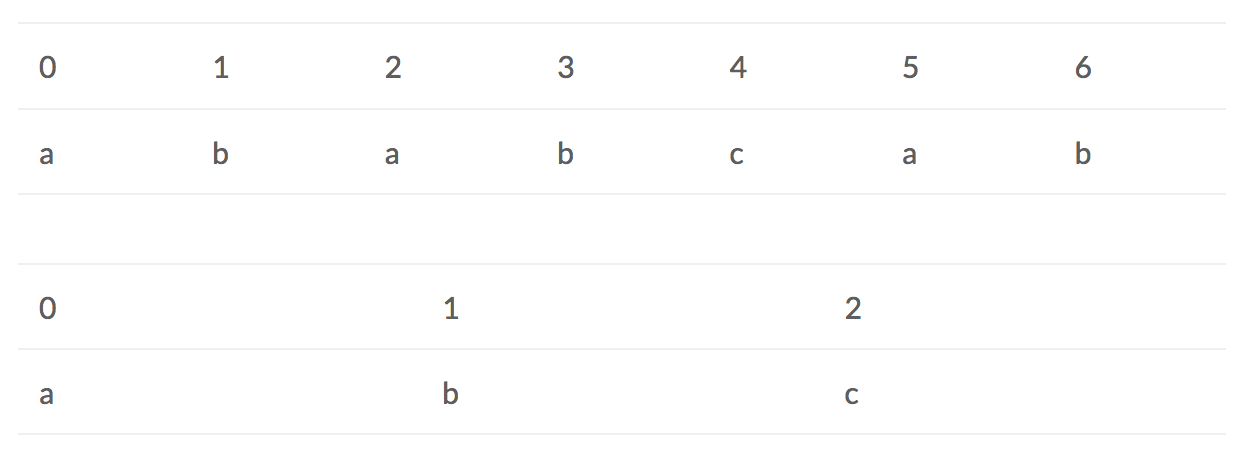
When si = 2 and ti = 2, we have already known that s0 = t0, s1 = t1, and t0 != t1. So s1 != t0. We can skip s1, start from s2 directly. So next time, we start from si = 2, ti = 0.
The most important part is check S, so we introduce another concept—“partial match table”, each element in this table stands for the maxim of the prefix has occurred before this index. Let’s see an example “abcabaca”.
for index = 2, c: prefix is a, ab, suffix is c, bc. There is no matching. So as the index = 0, 1. So before index = 3, we can know: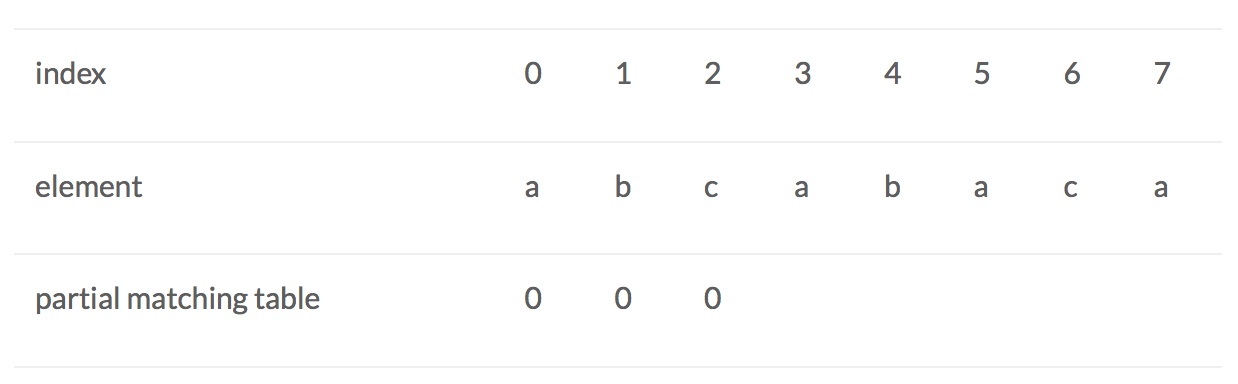
When index = 3, a : prefix is a,ab,abc, sufix is a,ca,bca. We find that ‘a’ equas ‘a’. And the length of ‘a’ is 1, so we update the partial matching table to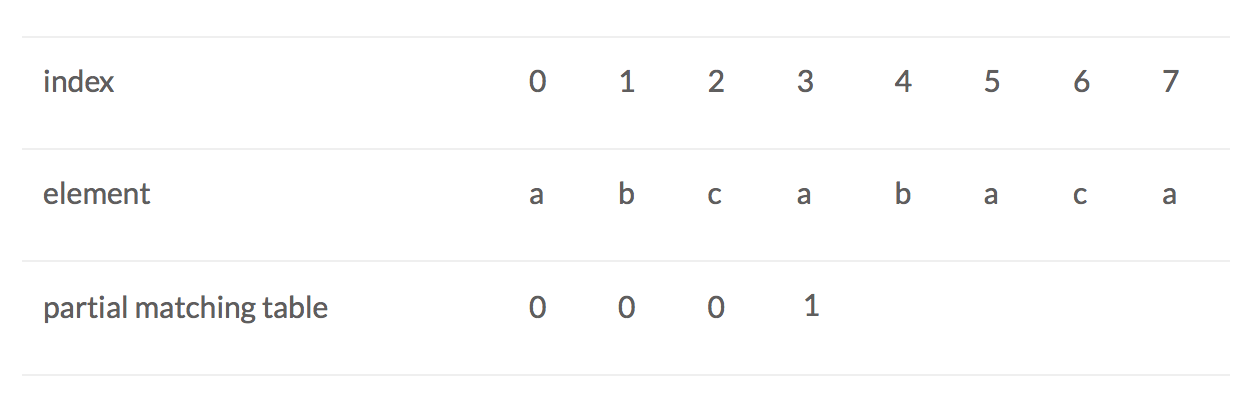
When index = 4, b: prefix is a,ab,abc, abca, sufix is b,ab, cab, bcab. We find that ‘ab’ equals ‘ab’. And the length of ‘ab’ is 2, so we update the partial mathcing table to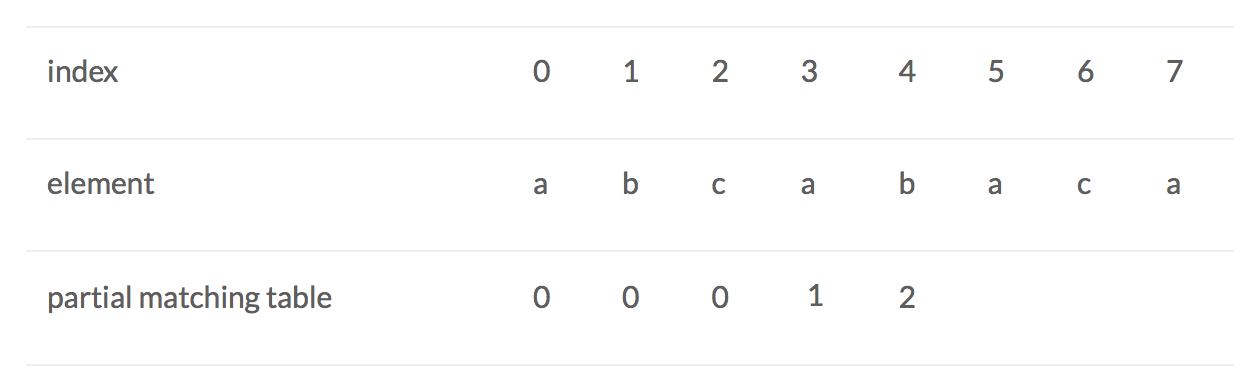
When index = 5, a: prefix is a, ab, abc, abca, abcab, sufix is a, ba, aba, caba, bcaba. We find that ‘a’ equals ‘a’, and the length of ‘a’ is 1, etc. Repeat these steps, we can have the final partial matching table which is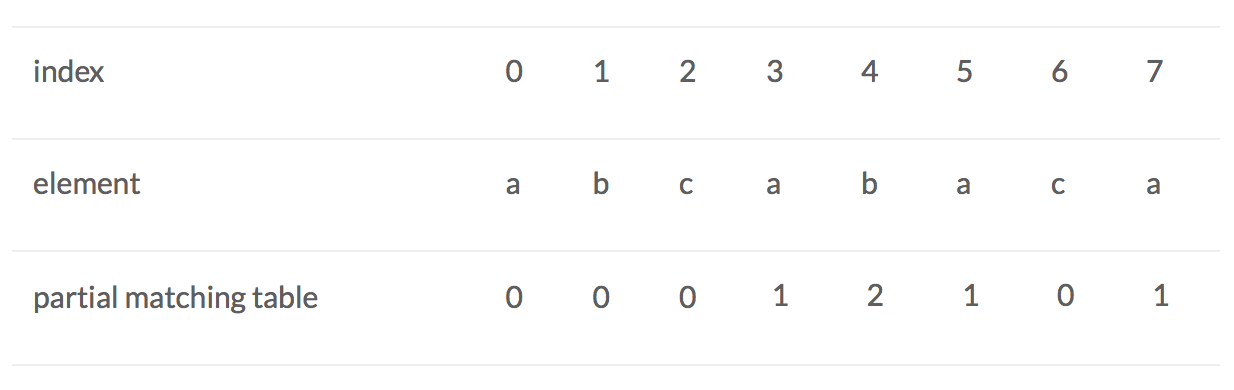
In order to make this partial matching table, the python code is as follow:
The next array will be the partial matching table. What I need to explain here is the while loop, when the character does not match. We need to go back to check, which one is the farthest index that equals to the current index and do not have any same prefix previously.
KMP Algorithm (part 2_Main):
Here is the main part, after we got the partial matching table, everything becomes easier(note: it should be the continue code for the previous code):
|
|
s always keeps increasing. We adjust p with partial matching table. When str[s] equals to pat[p]. We increase p and s one by one. But when it does not equal, if p equals to zero, that means the first element in pattern does not equal to the current index of s. So add 1 to s. However,it p != 0, then move p to the next[p-1]. The previous one that occurs in the substring, match it.
Further:
The partial matching table can be used to solve this problem:
Given a non-empty string check if it can be constructed by taking a substring of it and appending multiple copies of the substring together. You may assume the given string consists of lowercase English letters only and its length will not exceed 10000.It can be solved by just using the partial matching table. Do this return:
Hope this explanation help you guys have a better understanding of KMP algorithm. If you have any question, please leave a comment below. Thanks for reading it. 🙂